At work we use SVN for all our .NET Projects. Being a Microsoft Developer I’ve moved between multiple source control systems during my development life. Starting with Visual Source Safe, I moved to CVS, then to TFS (during its Beta stages) and finally fell in love and settled down with SVN. The love was strong enough to convert all .NET developers I work with, over to SVN! :)
Even today I highly encourage all Microsoft developers I meet outside the workplace to try-out SVN. With Tortoise and Ankh, the whole Visual Studio Integration and Explorer Integration is very easy to get and it (almost) feels as easy as VSS and as powerful as CVS. But this post is not about plugging-in SVN and related tools. It’s about starting a discussion on When-To-Branch and When-To-Work-On-The-Trunk (and When-To-Create-Tags).

Let me being by saying - It’s all about choices, opinions and which way works best your project. In the few years of using CVS (and then SVN) I’ve seen multiple ways in which the Trunk, Branches and Tags are used by multiple teams. Every team has its own “best practice” (the whole idea of a "best" practice is relative, because 'best' depends on so many factors :)) around when they should work on the trunk, when they tag their builds and when they create branches. Here are two most common approaches I’ve usually seen being used depending on the scenario and the project:
Approach 1 - Work on the Trunk, Tag on Each Release / Revision and Branch for Experiment
I’ve personally used this approach in projects where we have very frequent and agile releases. The approach basically involves:
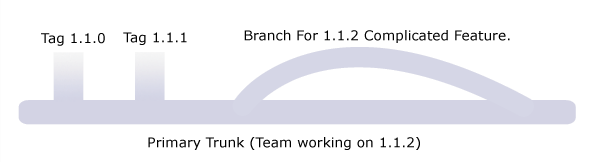
- The team constantly working on the Trunk.
- The trunk is tagged at Every Revision as well as at Every Release so that a snap shot of any version can be obtained.
- The team continues to work on the trunk after the tagging.
- If there’s anything the team wants to try out, they branch the code and merge back the changes to the trunk when done.
At any given day the Repository looks much like this:
What I love about this approach:
- The Simplicity and Speed at which team can work - Really helpful if you’re going to have weekly tags.
- Allows a “Branch-When-Needed approach” and leaves the branching-for-trying-out-complex-feature-implementations on Developers rather than imposing a strict policy on when to branch. They can freely do it as and when they want it.
- Easy to understand and work on, specially for VSS developers .
- Not having to change your Working Folder for each version change, since each developer is just concerned with the trunk and his own branches.
Cons:
- The Trunk may not always be functionally tested or 100% stable.
- A colleague brought this up during a discussion and his point was completely valid – “You can’t create patches for Release 1.1.1 and check it in to 1.1.1, if your trunk is at Release 1.2.” – (He’s all for Approach 2, I describe later in the post). Point valid and taken :) but I’m still not fully convinced that you really want to do something like that in a project that’s moving ahead really fast and throwing out revisions every week and a release every month or so; or for that matter, I'm not really sure if you want to do that for any project.
Personal Opinion: I don’t like the whole Idea of applying SVN patches to a branch of a version that has already been released and then checking-in the patch to that branch. If an immediate patch needs to be applied to an already released version e.g. 1.1.1, I can still checkout the tag, work on the checked out tag, create a patch and then ship the patch. It should be possible to apply the patch on both, the primary trunk (which is now at 1.1.2) and the checked out version of tagged build 1.1.1 (which needs immediate fixing). However what I don’t agree to is the idea of applying the patch to a 1.1.1 branch and then checking in the changes to 1.1.1 specially after 1.1.1 has been officially released. It just creates more confusion and makes things product versioning more complicated. Personally, I feel this is exactly what service packs are for.
Approach 2: Always work on the Branch Approach - I’ve seen a LOT of development teams take this approach. People claim this is really helpful when you just want to do milestone based branches and tags. The Idea is:
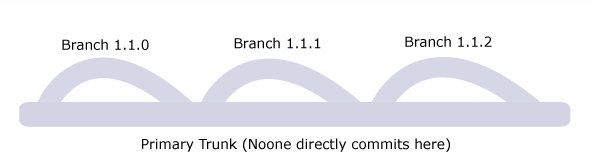
- For Every Milestone / Release create a New Branch.
- Everyone works on that branch.
- No-one works directly on the trunk, and because no-one works on the trunk, the trunk always represents the previous stable release.
- When the current release is tested, changes are merged to the trunk.
At any given point the repository looks like:
What's good about this approach:
- The Peace of mind that my trunk is always tested and stable.
- You can create patches for an older version and check-in the changes to the old version by checking in to the correct branch, even after the product has been released. (Personally, I don’t think this is a Plus, but a lot of development teams use this approach and I've been told by more than one very capable developer that this approach has worked for them in multiple projects).
- As a colleague / mentor recently pointed out - If you are doing development of two versions in parallel this approach can help. I would have to agree on that one. We've done the "continue to fix the trunk while we work on a new version in a branch" approach and when I look at this approach from that perspective it suddenly starts making a lot of sense.
- Honestly, I can’t think of other Plus-Points for never-work-on-the-trunk approach.
Cons:
- The whole idea of never working on the trunk makes it complicated for developers to create their own branch especially when they are already working on a branch. E.g. I want to work on “Feature A” which I am not sure will work out. If I am already on a Branch for version 1.1.2, it makes it a little complicated for me to branch again and merge my sub-branch with the 1.1.2 branch before the 1.1.2 branch is merged with the trunk. (I hope I haven’t confused you already, the more sub-branches from branches that you created the more complicated things become :))
And then there are mix and match of the above two approaches that I’ve seen a lot of teams use. For example a team which creates tags when a build is released, even while following the Approach 2 I described above or the approach where you continue to fix the trunk which holds the first version while you work on a second version on a branch. I've also worked with a Team where every SVN ( / CVS) command was wrapped with a custom wrapper command using Unix shell scripts and use of clients like Tortoise wasn't permitted.
How you use the SVN Branches, Tags, the trunk and in fact, the source control system, is completely based on what works best for the project and the team. Feel free to Mix and Match approaches to control the chaos with predefined guidelines but make sure you leave room for flexibility and agility.
There are no best practices! How to Manage code depends on the project, the team, how fast you want to go and multiple other scenarios. But it's always a good idea to have a set "SVN Working Practices" (notice the use of word 'working' instead of 'best' :)) for your Projects. Do you have a your SVN Working Practices Documented yet? If not, here's an excellent example you can use to get inspired. :)
Update [2/13/2007]: A colleague / mentor provided this link in a comment on my work blog. It's a practical repository of Branching Patterns for Parallel development. If you're interested in finding out about the various Branching Schemes out there and getting some guidelines on which scheme to use when, the article is a must-read!
Comments are closed.